Networking problems frequently impact application service delivery, but pinning them down can be difficult. Networks are becoming both larger and more complex, while applications can span multiple sites, including into and across multiple clouds. So what are the common networking issues, and why are they important to application delivery?
IT teams have found that identifying and resolving network problems has been a significant challenge for some time, but this wasn't always the case. Several decades ago, before modern switched networks, there were hubs. All nodes connected to a hub could see all other network traffic from all other nodes. Hubs made observing network traffic easy, but they were terribly inefficient. Eventually, switches became commonplace, and this reduced network visibility to broadcast traffic. VLANs, VXLANs and overlay networking reduced visibility into broadcast traffic as well. The need to inspect traffic never went away, but the means by which this inspection can occur changed as network themselves changed. In the days of the hub, any computer could spy on all other computers. Switches meant that traffic inspection had to be done inline, with the participation of the switch, or both. Virtualization and overlay networking added more solutions that had to participate: the virtualization hosts, software-defined networking controllers, and so forth.
Today, cloud computing has further reduced networking visibility. Organizations using public clouds do not have direct control of the networks that underlie the applications and services they use. This is gradually being resolved as cloud providers offer up more details about their networking via APIs. All of this complexity combines with the increasingly multi-infrastructure nature of today's applications to make monitoring data flows such a challenge. Tracking communications between all the workloads which form a single service could require communicating with dozens of individual infrastructure elements. These multiple sources of information then have to be analysed and presented in a comprehensible fashion. Humans aren't really good at looking at hundreds of data flows across dozens of network segments and identifying which of them join together to form a single data flow between workloads.
In addition to all of the above, the structure of networks can play a significant role. Performance is often dictated by where workloads live in relation to one another across an organization's network infrastructure. Network design also impacts how certain security and monitoring solutions can be deployed, and the restrictions imposed by those solutions can further impact the end-user experience.
North-South
The classic three tier network design has multiple servers in a rack connecting to a Top-of-Rack (ToR) access switch, and multiple ToR access switches connecting to distribution switches above them. Multiple distributions switches connect to the core switches, ultimately allowing all servers to communicate.
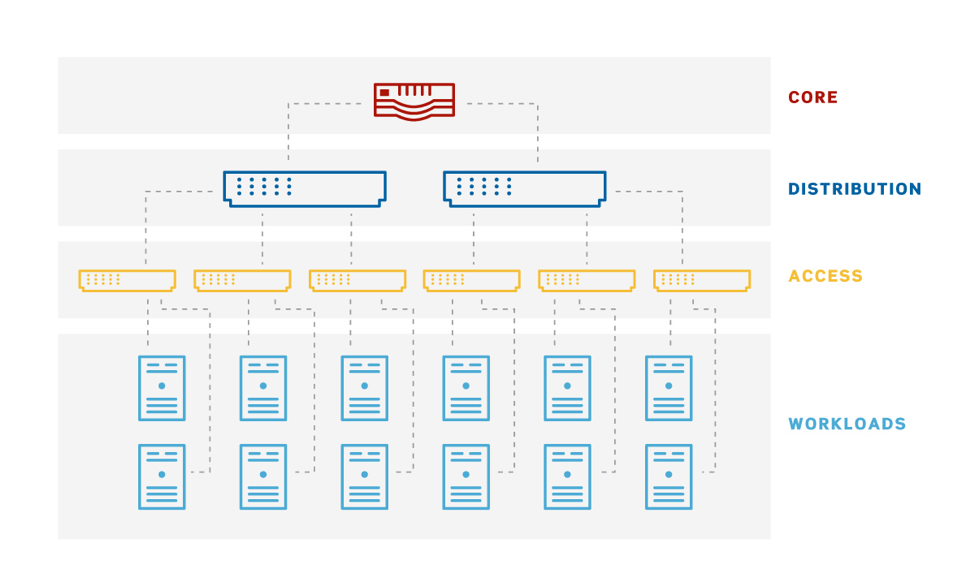 Figure 1 - The classing 3-tier network design
Figure 1 - The classing 3-tier network design
A server communicating with another server on its own rack only transits that rack's ToR switch. This means that communication between the two servers only impacted by the network connections each of the participating servers has with the ToR switch. If the two servers seeking to communicate are located on different racks, then there are now at least four network connections involved: the two that connect the servers to their respective ToR switches, and the connections between those ToR switches and the distribution switch. The network connections between the ToR switches and the distribution switches carry traffic for multiple workloads, meaning that communication between two servers can now be impacted by the communications occurring between other pairs of servers.
The higher up the stack one goes, the more other servers can potentially impact the communication between two servers. This means that communications between "closer" servers are more predictable than communications between "far" servers, where proximity is determined by the number of network connections between the two servers that wish to communicate. Networking traffic that transits multiple layers of switches (in other words, network traffic that goes beyond the ToR switch) is referred to as "north-south" networking. North-south networking usually includes all network traffic bound for the internet, or for other sites. This is because internet and WAN connectivity typically hang off the network's core, as they are a central resource all workloads need access to.
East-West
East-west communication is the term used to discuss communication between workloads, though this can become somewhat confusing as complexity increases. Two workloads communicating east-west across the network may also generate north-south traffic if their communications need to travel across multiple layers of the network. The only pure east-west traffic would be traffic between two devices on the same switch. To contrast, the only pure north-south traffic is traffic that leaves the organization's network entirely. Everything else is both communication between two devices or workloads within an organization's network and it is communication that transits multiple layers of the stack.
Today's networks make this all more complicated by adding multiple additional tiers of networking within a single data center, as well as adding multiple data centers across multiple sites and multiple clouds. In addition, modern networks are rarely strictly hierarchical. Network fabrics can be built with interconnectivity between any switches. When appropriately designed, network fabrics reduce north-south congestion by offering multiple data paths, ultimately making east-west traffic less "expensive".
The Importance of Network Visibility
In order to identify network bottlenecks, administrators need to have visibility of data flows as they transit the network. It isn't enough to see which network links are congested, administrators need to understand which workloads are attempting to communicate across a given network link, and why. In some cases, network congestion can be resolved by moving different workloads that are part of a single application closer together, so that there are fewer network links between them. In many cases, network congestion is caused by a single service whose individual workloads were non-optimally deployed.
Network visibility isn't only of use to network administrators, however: application owners can benefit greatly from understanding how services they are building interact with the network(s) upon which they operate. Network visibility's utility may be as simple as providing evidence to service owners that there exists a congestion problem (and where that problem is). Being able to tell the network administrators "there's a problem right here, and here's the proof" can speed problem resolution.
Network visibility can also allow application owners to make rational judgement calls about where to place workload components in the first place. If a link is already oversubscribed, requiring workloads within a service to communicate across that link is likely to result in disappointment.
Interested in seeing Uila's Application-centric IT monitoring solution for Network Visibility and troubleshooting in action? Watch the Interactive Demo or Request a Free Application Performance Assessment of your Data Center.
Subscribe
Latest Posts
- How Data Center System Administrators Are Evolving in today's world
- Microsoft NTLM: Tips for Discontinuation
- Understanding the Importance of Deep Packet Inspection in Application Dependency Mapping
- Polyfill.io supply chain attack: Detection & Protection
- Importance of Remote End-User Experience Monitoring
- Application and Infrastructure Challenges for Utility Companies
- Troubleshooting Exchange Server Issues in Data Centers
- Importance of Application Dependency Mapping for IT Asset Inventory Control
- Navigating the Flow: Understanding East-West Network Traffic
- The imperative of full-stack observability



