Many clouds tend toward what has become known as "t-shirt sizing" of workload instances. Especially where Infrastructure-as-a-Service (IaaS) virtual machines (VMs) are concerned, cloud provider offerings are typically classified as small, medium, large, and so forth. This can be the source of inefficiency that ultimately costs a significant amount of money.
T-shirt sizing bundles a fixed amount of RAM and storage with a given number of virtual CPU cores. If you need more of a resource – RAM, for example – you must consume a larger sized workload instance. You may not need the additional CPU cores, or the additional storage, but to get that additional RAM, you must pay for them anyway.
Not all cloud providers operate on a t-shirt pricing model, though it is by far the most common. Some providers – for example, Iland – have made a name for themselves with a Virtual Data Center (VDC) model instead.
In the VDC model, customers rents a block amount of resources – RAM, CPU, storage – which is made available to their VDC. The customer, which has full control of their VDC, can then allocate resources as they see fit. Some VDC-based providers can even nest VDCs, so an organization may purchase a large block of resources at the organization level, then break that into VDCs that would be consumed by individual business units.
These form the two primary models for cloud resource consumption. T-shirt sizing is focused on the resource consumption of individual workloads, while VDC-based clouds focus on the overall resource consumption of a tenant. Hypothetically, VDC-based clouds allow for more efficient use of resources, because they allow organizations to assign workloads only the resources they absolutely require.
In practice, however, human nature often gets in the way.
Margins of Error
One of the most important activities of the cloud administrator is right-sizing resource usage. Cloud computing costs can get out of hand quickly, and making sure that one's organization is not overspending can itself become a full time job.
To contrast, resource right-sizing has traditionally been a nice-to-have feature for on-premises administrators of traditional infrastructure. Systems administrators tend to approach IT infrastructure design just as any engineer would approach designing a bridge: they build in a significant margin of error.
Application administrators request more resources from infrastructure administrators than they really need, just in case they need it at some future point. Infrastructure administrators purchase more infrastructure than they really need, just in case they need it at some future point. And so on.
The end result is that on-premises data centers aren't particularly efficient. Some technologies – such as thin provisioning and CPU oversubscription – help compensate for administrators' tendency to build in margins of error. Unfortunately, these technologies don't entirely eliminate inefficiency.
Until recently, this approach to computing wasn't viewed as much of a problem. Virtualization was allowing organizations to consolidate multiple workloads onto a single physical machine. Containerization allowed for even higher workload densities.
An average organization might demonstrate an average of 40% efficiency in resource utilization on-premises. A conscientious IT team might get that as high as 70%, and this is often considered quite good, in large part because IT teams have traditionally compared their resource utilization to running workloads on dedicated servers. In organizations running dedicated servers for each workload, hardware resource utilization can be as low as 5%, which makes virtualization look good, even in poorly optimized data centers.
Square Pegs, Round Holes
The often lackadaisical approach to efficiency that’s popular among on-premises administrator doesn't translate well to cloud computing. Any organization only achieving 40% efficiency with their cloud computing workloads is going to be in for a nasty shock when the bill arrives.
Resolving resource usage inefficiency starts with baselining your current infrastructure. Administrators need to know what workloads they have and what resources are reserved for those workloads, as well as what those workloads consume at idle, average and peak consumption.
Once this data has been gathered, the data analysis begins. Which workloads are improperly sized? Which clusters or VDCs could accept which workloads, and which workloads should be assigned to which t-shirt size of instance?
For small enough organizations, this sort of data could be collected and analyzed manually. As the number of workloads increases, however, so too does the burden of performing this sort of analysis. Then there’s the additional chore of keeping it up to date; nobody wants to be responsible for maintaining a spreadsheet for resource optimization when there are 5,000 workloads!
Automation
Workloads change over time. These variations can ebb and flow with business hours, or be tied to weekly or monthly events, such as the generation of reports. Changes in workloads are also common due to seasonal changes, special events, and – hopefully – the growth of the organization.
Ideally, all workloads would be constantly monitored, both for problems and for resource usage. Monitoring is at the core of both incident response and resource optimization. Increasingly, cost optimization cannot be reasonably performed independent of incident monitoring.
Monitoring all workloads, as well as the infrastructure upon which they operate, allows for automated root cause analysis. If all 200 workloads using a given storage array suddenly start having problems, then that storage array is likely the culprit.
This information is also important when assessing workloads for resource usage. If, for example, the storage that underpins a given workload is operating at or near the red line, it’s safe to assume that if that workload were moved to infrastructure with more performant storage, its resource utilization profile would change. Eliminate one bottleneck and another will appear – workloads are always constrained by something.
Services
Modern resource optimization relies on a combination of monitoring and big data analytics. Data is collected and stored, spanning years. Sizing recommendations are generated based not only on current real-time data, but by analyzing historical usage. Increasingly, resource optimization requires looking at workload utilization organization-wide, instead of simply analyzing individual workloads, as the complex interactions between workloads tell a more complete tale than any workload taken in isolation.
Just as a storage array can bottleneck an individual workload, many workloads often work together to form a single service. A slow website might not be the result of inadequately fast storage, networking, or other resources; it may be that there aren’t enough database instances in play, or that the load balancer is incorrectly sized.
It is here that software is absolutely required for resource management. While it’s possible to do basic baselining and sizing with a spreadsheet, understanding how all the various pieces of infrastructure affect each workload, and how those workloads affect one another, is exactly the sort of problem computers are good at, and humans are not.
Uila Resource Management
Uila monitors both workloads and the infrastructure they run on. As a result, Uila captures and stores information from numerous data points about each workload. This information is then analyzed to deliver up-to-date recommendations for resource sizing, and workload migration.
Uila can help organizations optimize their IT resource usage, whether workloads execute on-premises or in the public cloud. Uila can also extrapolate future IT needs based on historic consumption and growth rates, helping administrators ensure they always have the resources they need, when they need it – and not before.
With Uila, administrators can stop building in generous margins of error into their on-premises infrastructure, while cost-optimizing their usage of public cloud infrastructures. Uila takes the unpredictability out of IT.
For more details on Uila's Resource Rightsizing recommendations, click here. 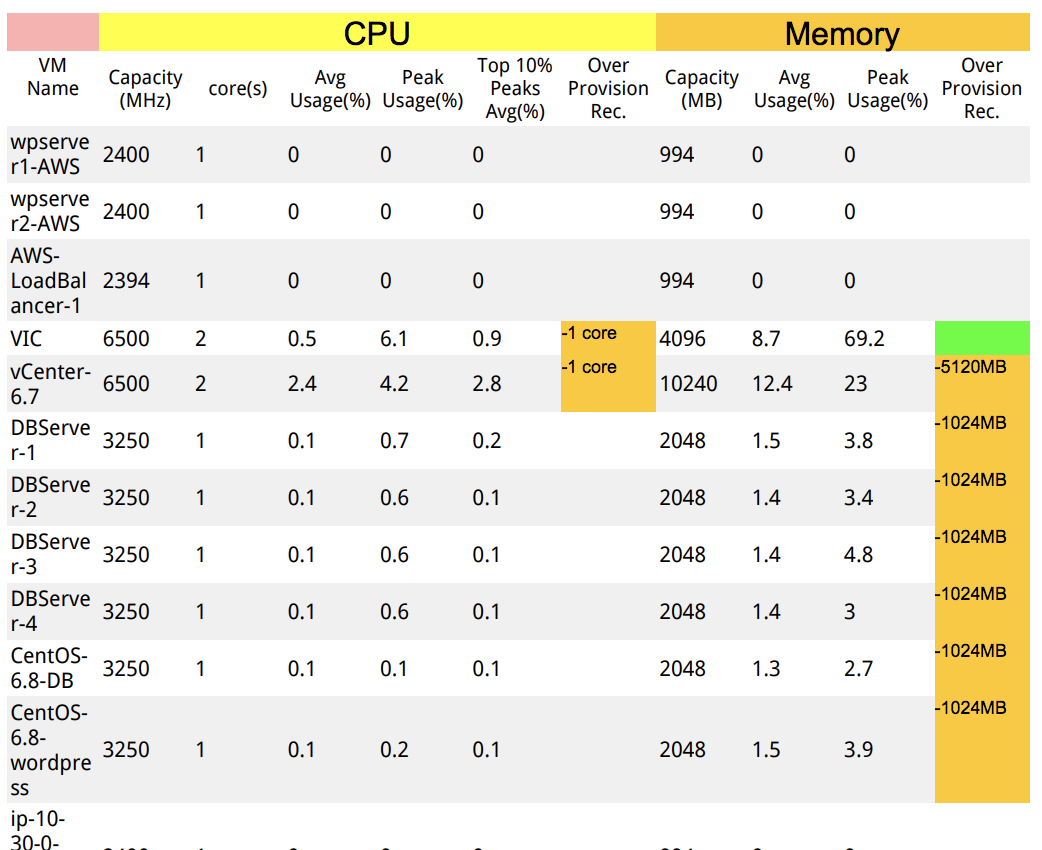
Subscribe
Latest Posts
- How Data Center System Administrators Are Evolving in today's world
- Microsoft NTLM: Tips for Discontinuation
- Understanding the Importance of Deep Packet Inspection in Application Dependency Mapping
- Polyfill.io supply chain attack: Detection & Protection
- Importance of Remote End-User Experience Monitoring
- Application and Infrastructure Challenges for Utility Companies
- Troubleshooting Exchange Server Issues in Data Centers
- Importance of Application Dependency Mapping for IT Asset Inventory Control
- Navigating the Flow: Understanding East-West Network Traffic
- The imperative of full-stack observability



